
Полный разбор установки llama.cpp, загрузки модели и подключения Open WebUI
Плата: Orange Pi 6 Plus
RAM: 16 ГБ
GPU: не использовался
Система: Ubuntu 24.04
Модель: Mistral 7B Instruct v0.2 Q4_K_M (GGUF)
Цель — полностью локальный AI-ассистент, работающий офлайн.
ЭТАП 1 — Подготовка системы
Обновление системы и установка базовых пакетов для компиляции:
sudo apt update && sudo apt upgrade -y sudo apt install git build-essential cmake python3-venv python3-pip -y
ЭТАП 2 — Установка и сборка llama.cpp
Переходим в домашнюю директорию, клонируем репозиторий и выполняем сборку.
cd ~ git clone https://github.com/ggerganov/llama.cpp cd llama.cpp make
После завершения сборки проверяем наличие исполняемых файлов в каталоге build/bin/:
ls build/bin
В списке присутствуют ключевые файлы:
llama-cli(для работы в терминале)llama-server(для поднятия API)
Проверяем работоспособность:
./build/bin/llama-cli --help
Справка отобразилась — сборка прошла успешно.
ЭТАП 3 — Установка huggingface_hub (ошибка PEP 668)
При попытке установить пакет глобально:
pip install --upgrade huggingface_hub
Возникает ошибка:
externally-managed-environment
Причина: Ubuntu 24.04 блокирует глобальную установку pip-пакетов для предотвращения конфликтов с системным менеджером пакетов.
ЭТАП 4 — Создание виртуального окружения
Обходим ограничение с помощью venv:
python3 -m venv hf_env source hf_env/bin/activate pip install --upgrade pip pip install huggingface_hub
Проверяем установку (команда hf, а не huggingface-cli):
hf --help
ЭТАП 5 — Регистрация и получение токена Hugging Face
- Регистрируемся на huggingface.co.
- Переходим: Profile → Settings → Access Tokens → Create new token (тип: Read).
- Авторизуемся в терминале: hf auth loginВставляем токен. На вопрос о добавлении git credential отвечаем
N.
ЭТАП 6 — Скачивание модели
Создаем каталог для моделей и скачиваем Mistral 7B в квантовании Q4_K_M (оптимальный баланс качества и производительности).
mkdir ~/models cd ~/models hf download \ TheBloke/Mistral-7B-Instruct-v0.2-GGUF \ mistral-7b-instruct-v0.2.Q4_K_M.gguf \ --local-dir .
Размер файла: ≈ 4.37 ГБ.
После загрузки отключаем виртуальное окружение:
deactivate
ЭТАП 7 — Первый запуск модели (CLI)
Переходим в каталог llama.cpp и запускаем модель для проверки. Флаг -i (интерактивный режим) в текущих версиях может не работать, используем прямой ввод.
cd ~/llama.cpp ./build/bin/llama-cli \ -m ~/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf \ -c 4096 \ -p "Объясни, что такое нейросеть простыми словами."
Модель успешно загружается и выводит ответ в терминале.
ЭТАП 8 — Запуск API сервера
Запускаем llama-server, который создаст OpenAI-совместимый API.
./build/bin/llama-server \ -m ~/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf \ -c 4096 \ --host 0.0.0.0 \ --port 8080
Проверяем доступность API из другого терминала:
curl http://localhost:8080/v1/models
Ожидаемый ответ:
json
{
"id":"mistral-7b-instruct-v0.2.Q4_K_M.gguf",
"owned_by":"llamacpp"
}
Сервер работает корректно.
ЭТАП 9 — Встроенный веб-интерфейс llama-server
После запуска сервера в браузере доступен простой интерфейс по адресу:
http://<IP-адрес-платы>:8080
(например, http://192.168.1.99:8080)
Через него можно отправлять запросы для быстрого тестирования.

ЭТАП 10 — Установка Open WebUI
Для более комфортного использования устанавливаем Open WebUI в отдельном виртуальном окружении.
cd ~ python3 -m venv webui source webui/bin/activate pip install --upgrade pip pip install open-webui
Запускаем веб-интерфейс:
open-webui serve --host 0.0.0.0 --port 3000
Адрес доступа:
http://192.168.1.99:3000
При первом входе потребуется создать учетную запись администратора.

ЭТАП 11 — Подключение Open WebUI к llama-server
В интерфейсе Open WebUI переходим:
Настройки администратора (Admin Settings) → Подключения (Connections) → OpenAI API
- Base URL: меняем с
https://api.openai.com/v1наhttp://192.168.1.99:8080/v1 - API Key: вводим любое значение, например,
test(llama-server не проверяет ключи).
После сохранения модель mistral-7b-instruct-v0.2.Q4_K_M.gguf автоматически появится в списке доступных.
ЭТАП 12 — Проблема языка
При первом общении модель начала отвечать на китайском языке. Это распространенная проблема для некоторых сборок базовых моделей.
Решение: добавлен системный промпт в настройках чата Open WebUI:
Ты — полезный AI-ассистент. Всегда отвечай на русском языке.
После этого ответы стали корректными (русскими).
ЭТАП 13 — Проблема галлюцинаций
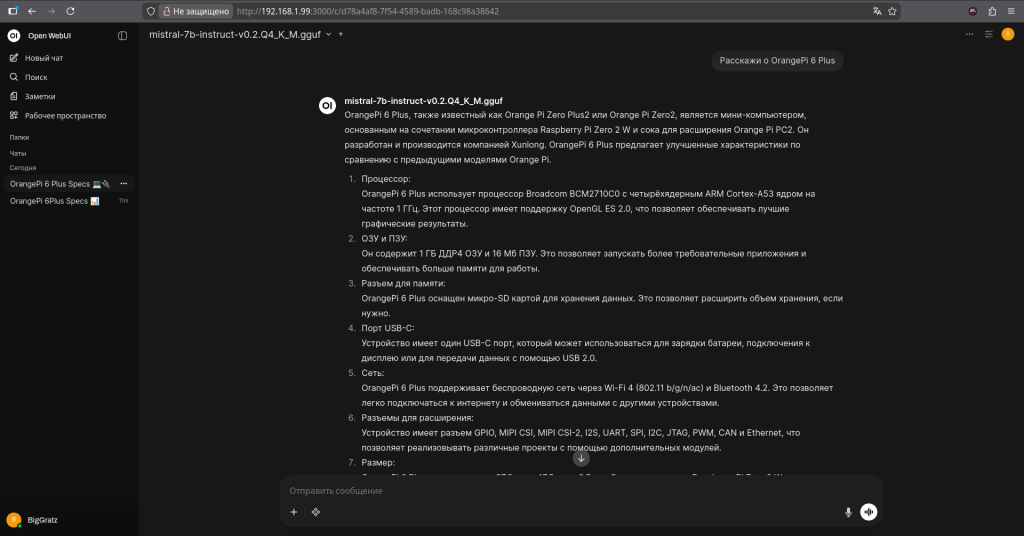
В ходе тестирования была выявлена критическая особенность: модель склонна выдумывать факты (галлюцинировать).
При запросе технических характеристик платы Orange Pi 6 Plus модель выдала правдоподобные, но полностью вымышленные данные, которых нет в реальности.
Причины:
- Размер модели: 7 миллиардов параметров — это относительно небольшая модель, склонная к обобщениям.
- Квантование (Q4): Сжатие модели для экономии RAM снижает точность рассуждений.
- Отсутствие RAG: Модель не имеет доступа к интернету или локальной базе данных с документацией.
- Принцип работы: LLM предсказывают следующее слово, опираясь на статистические закономерности, а не обращаются к базе фактов.
Итог
На Orange Pi 6 Plus (16 ГБ RAM) удалось successfully развернуть полноценный локальный аналог ChatGPT:
- ✓ Скомпилировать
llama.cppиз исходников. - ✓ Скачать и запустить языковую модель Mistral 7B.
- ✓ Поднять OpenAI-совместимый API-сервер.
- ✓ Установить и настроить стильный веб-интерфейс Open WebUI.
- ✓ Получить полностью автономного AI-ассистента, работающего офлайн.
Главное ограничение: неточность и выдумывание фактов. Как показало тестирование, Mistral 7B Instruct в связке с локальным запуском склонна к галлюцинациям — она может выдавать вымышленные данные, сохраняя видимость уверенности. Это делает её пригодной для творческих задач, написания кода или текстов, но требует критической проверки фактов.
Следующим шагом будет тестирование других моделей (например, Qwen2.5 7B или русскоязычных Saiga/YandexGPT), а также внедрение RAG-систем (Retrieval-Augmented Generation) для подключения к документации и повышения точности ответов.